Implicit Neural Representations (INR) or neural fields have emerged as a popular framework to encode multimedia signals such as images and radiance fields while retaining high-quality.
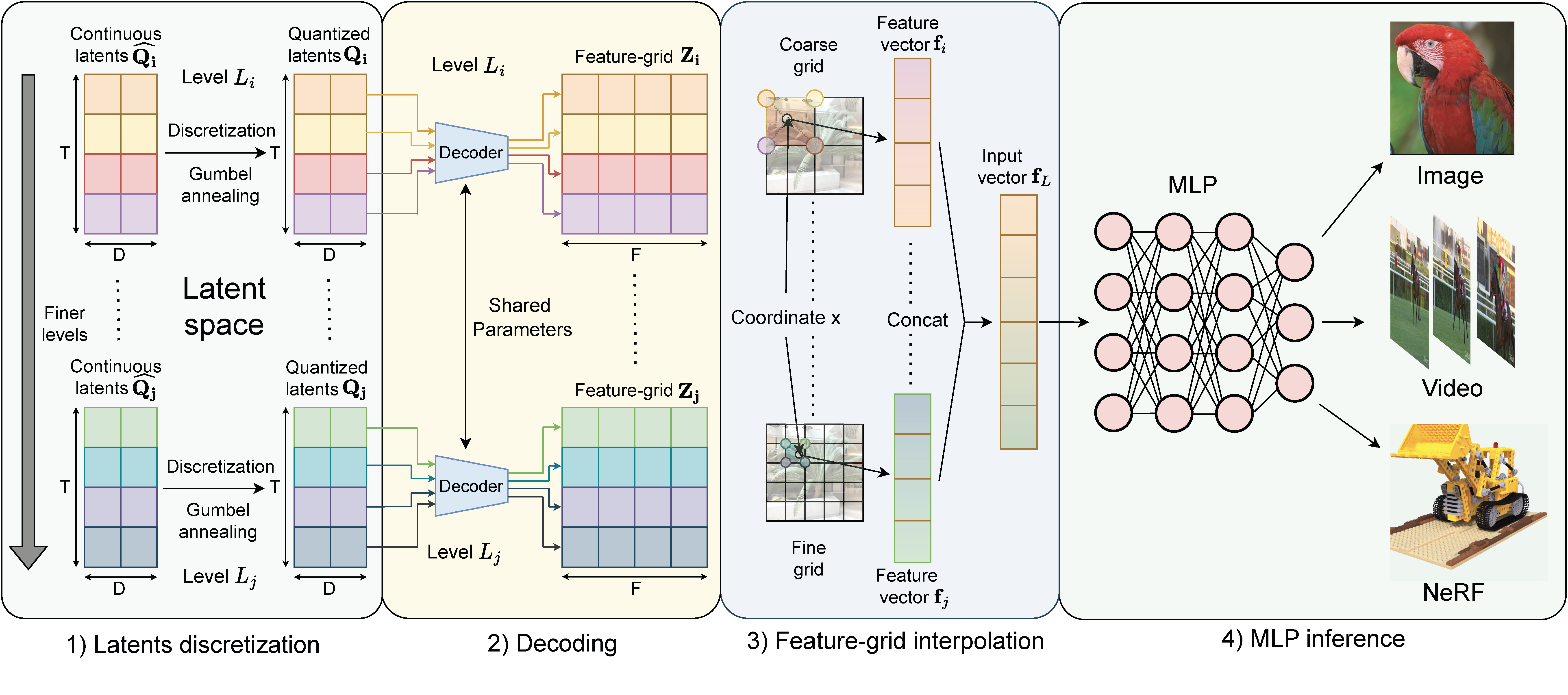
Recently, learnable feature grids (Instant-NGP) have allowed significant speed-up in the training as well as the sampling of INRs by replacing a large neural network with a multi-resolution look-up table of feature vectors and a much smaller neural network. However, these feature grids come at the expense of large memory consumption which can be a bottleneck for storage and streaming applications.
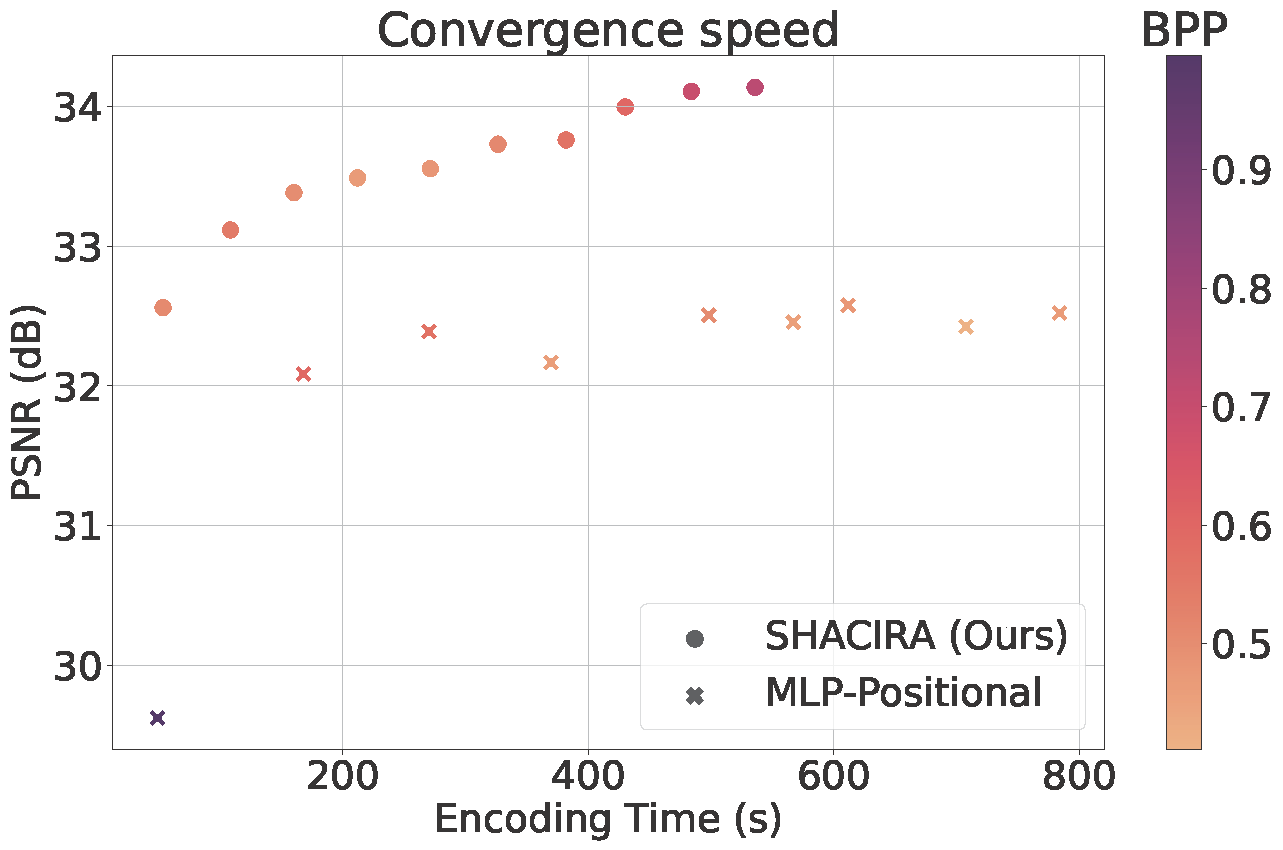
In this work, we propose SHACIRA, a simple yet effective task-agnostic framework for compressing such feature grids with no additional post-hoc pruning/quantization stages. We reparameterize feature grids with quantized latent weights and apply entropy regularization in the latent space to achieve high levels of compression across various domains. Quantitative and qualitative results on diverse datasets consisting of images, videos, and radiance fields, show that our approach outperforms existing INR approaches without the need for any large datasets or domain-specific heuristics.




@InProceedings{Girish_2023_ICCV,
author = {Girish, Sharath and Shrivastava, Abhinav and Gupta, Kamal},
title = {SHACIRA: Scalable HAsh-grid Compression for Implicit Neural Representations},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {17513-17524}
}